Executive summary

The DensePose model is an extension of the original COCO dataset. The additional images contain the human body annotated with labels that map image pixels to the 3D surface of the human model.
Applications of DensePose
The DensePose model with its dense pose estimation offers integration into diverse fields. We will look at possible scenarios where the model can be implemented in this section.
Augmented Reality (AR):
The field of AR gets a boost due to DensePose. As AR depends upon cameras and sensors, DensePose provides an opportunity to overcome the hardware prerequisites. This allows for a better and more seamless experience for the users. Moreover, using DensePose we can create virtual avatars of the users, and allow them to try on different outfits and apparel in the simulation.
Animation and VFX:
The model can be used to generate and simplify the process of character animations, where the human motion is captured and then transferred to digital characters. This can be used in movies, games, and simulation purposes.
Sports Analysis:
DensePose model can be used in sports to analyze athlete performance. This can be done by tracking body movements and postures during training and competitions. The data generated can then be used to understand movement and biomechanics for coaching and analytic purposes.
Medical Field:
The medical field and especially chiropractors can use DensePose to analyze body posture and movements. This can equip the doctors better for treating patients.
E-Commerce:
DensePose can be used by customers to virtually try on clothes and accessories, and visualize how they would look in them before they commit to buying decisions. This can improve customer satisfaction and provide a unique selling point for the businesses.
Limitations of DensePose
In the previous section, we discuss the potential uses of the model. However, there are limitations that DensePose faces, and therefore it requires further research and improvement in these key areas.
Lack of 3D Mesh:
Although DensePose provides 3D mesh coordinates, it does not yield a 3D representation. There is still a developmental gap between converting an RGB image to a 3D model directly.
Lack of Mobile Integration:
Another key limitation of the DensePose model is its dependency on computational resources. This makes it difficult to integrate DensePose into mobile and handled gadgets. However, using cloud architectures to do the computation can fix this problem. But, this creates a high dependence on the availability of high-speed internet connection. A majority of people lack high-speed connections at home.
DensePose: Facebook's Breakthrough in Human Pose Estimation - viso.ai
DensePose is a Deep Learning model for dense human pose estimation which was released by researchers at Facebook in 2010. It performs pose estimation without requiring dedicated sensors. It maps standard RGB images to a 3D surface representation of the human body, creating a dense correspondence between 2D images and 3D human models.
As a result, the dense pose created by this model is so much richer and detailed compared to standard pose estimation.
When we look at its potential applications, it is endless. DensePose can be used in the field of AR/VR, but apart from that, it opens various creative applications, for example, you can try out clothes and see how they would look on your body before buying them or use this Deep Learning model for performance analysis in sports to track player movements and biomechanics.
In this blog, we will look into the workings of DensePose and how it converts a simple picture into dense human poses of the human body, without the need for dedicated sensors.
About us: Viso Suite is the premier computer vision infrastructure for enterprises. With the entire ML pipeline under one roof, Viso Suite eliminates the need for point solutions. To learn more about how Viso Suite can help automate your business needs, book a demo with our team.
High-Level Overview of DensePose
As we discussed above, DensePose maps each pixel in an image to a UV-created 3D model. To perform this, DensePose goes through the following intermediatory steps:
- Input Image
- Feature Extraction with CNN
- Region Proposal Network (RPN)
- RoI Align
- Segmentation Branch for body parts segmentation
- UV Mapping using the UV Mapping Head
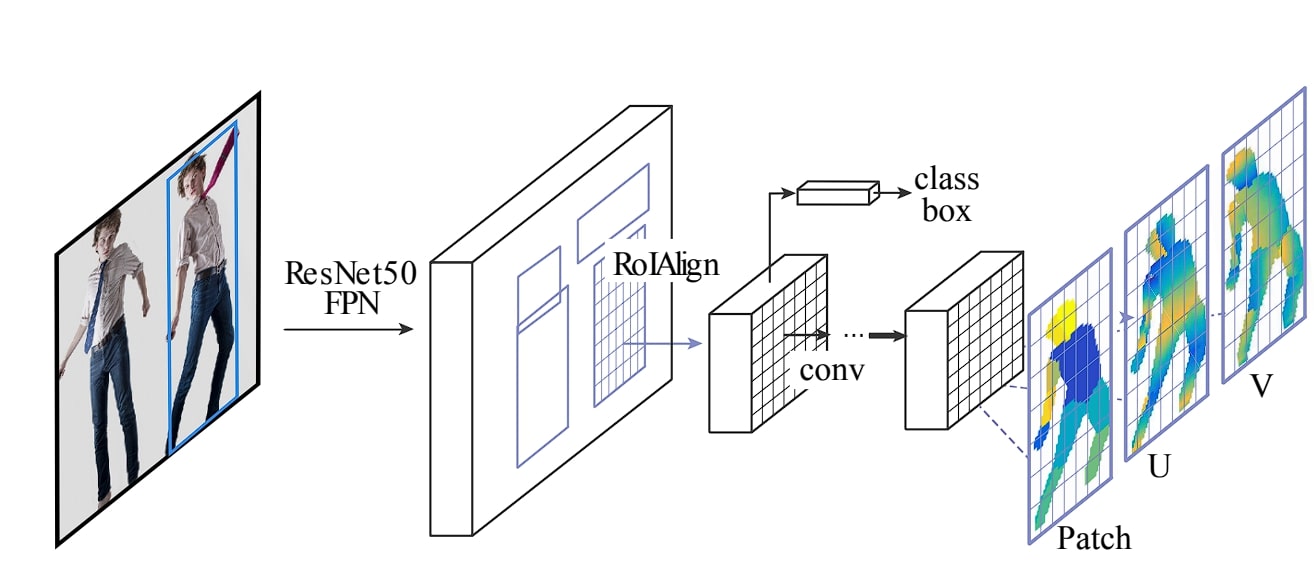
Let us discuss the working of the DensePose model.
Feature Extraction
Input Image:
- We provide the input image to the model.
Feature Extraction with a Convolutional Neural Network (CNN):
- In this first step of the process, DensePose passes the given image into a pre-trained Convolutional Neural Network (CNN), such as ResNet. ResNet extracts features from the input image.
Region Proposal Network (RPN):
- DensePose uses a Region Proposal Network (RPN) to generate proposals for regions (bounding boxes around human body parts). This step is important as it helps to narrow down the areas the model needs to focus on.
RoI Align and Region of Interest-Based Features:
- The proposals generated by the RPN network are further refined using Region of Interest (RoI) Align. This technique further improves the location of proposed regions.
Pose Estimation:
- Once the regions are proposed, the model performs instance segmentation to differentiate between multiple human body parts that might be present in the image. From this segmentation, it creates a human pose.
UV Mapping
For each detected human pose, the DensePose model predicts UV coordinates for each pixel within the region of interest. UV mapping is a process used in computer graphics to map a 2D image onto a 3D model. “u” and “v” here means the coordinates in a 2D model.
DensePose uses a standardized 3D model of the human body, known as the canonical body model. This model has its surface parameterized with UV coordinates. To do this, a dedicated UV mapping head is used.

UV Mapping Head:
- This is the part of the DensePose network that specializes in taking the RoI Aligned features to predict the UV coordinates. This head consists of multiple convolutional layers followed by fully connected layers to refine the prediction.
- The output from this head is a dense correspondence map where every pixel within the region of interest is assigned a UV coordinate, which maps it to the 3D body model.
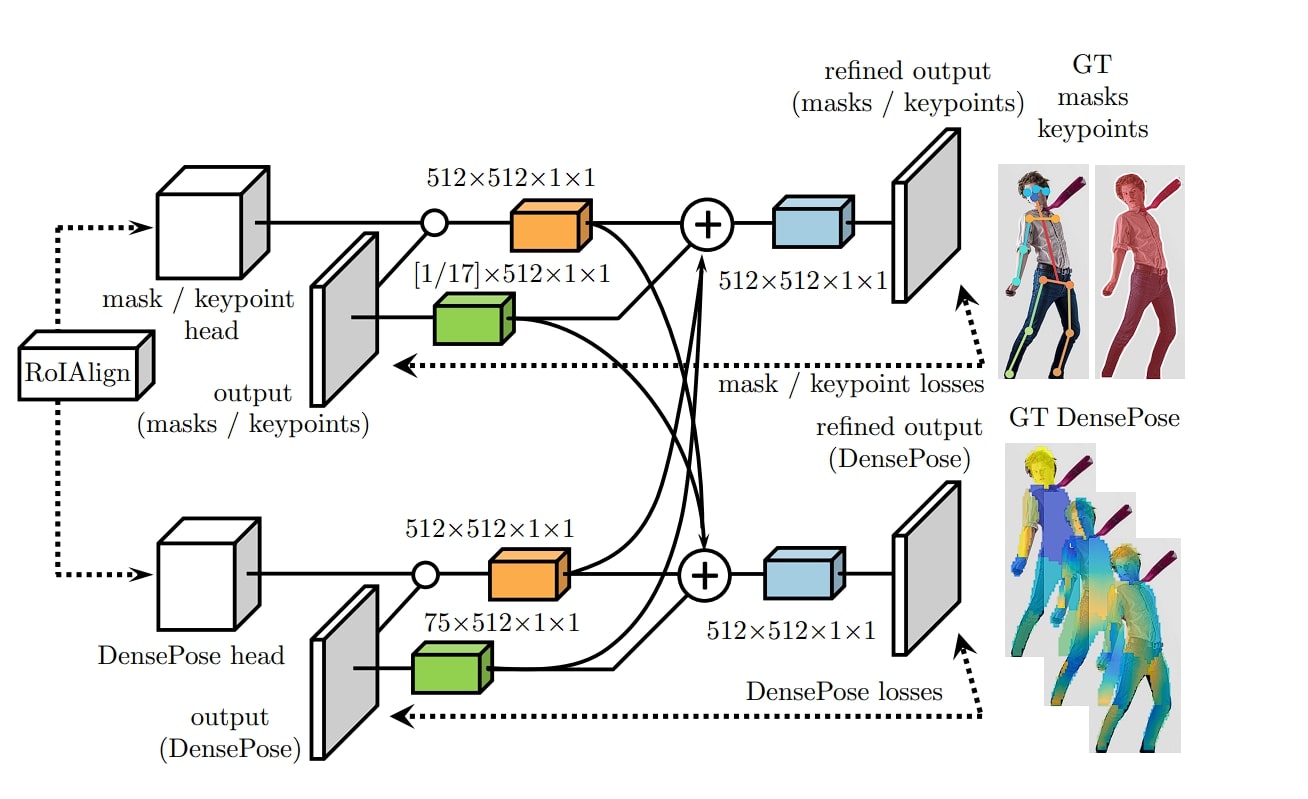
Architecture of DensePose model
In the above section, we looked at an overview of the steps the image goes through in the DensePose network. Here is the detailed architecture:
- Backbone Network: Uses ResNet for feature extraction
- Region Proposal Network (RPN): Proposes Region of interest using Mask-RCNN
- RoIAlign Layer: Instead of using Region of Interest (RoI), DensePose uses a RoI Align layer.
- Segmentation Mask Prediction: A separate branch inside the RPN network to segment different human body parts.
- DensePose Head: Maps body parts to UV coordinates
- Keypoint Head: Used for pose estimation
Backbone Network
As we discussed above, DensePose uses ResNet as its backbone, which is used to extract features from the given image to facilitate the process of mapping UV coordinates.
ResNet is a deep learning model made up of convolution layers. What differentiates ResNet from a standard convolution network is that it uses residual blocks, in this, the input from one layer is added directly to another layer later in the network, which helps with combating the vanishing gradient problem found in deep Neural Networks.
Region Proposal Network (RPN)
In DensePose, the authors used Mask-RCNN to detect potential regions of interest in the human body. It works by taking input from features extracted by the backbone network. Then it conducts several steps to generate bounding box proposals using anchor boxes. Here are the steps involved:
- Anchor Boxes: Anchor boxes are reference boxes that are predefined with various scales and aspect ratios. The model places these boxes and predicts whether a particular human body is present inside the box or not. You might be wondering why use these.
The answer is that without this the model will have an infinite number of possible places to look into; by using anchor boxes, the model is limited to certain possibilities only. Anchor boxes give a starting point to the model. - Objectness Scores: The RPN predicts objectness scores for each anchor box to calculate the likelihood of containing an object (in this case, human body parts in DensePose).
- Bounding Box Regression: Once the model selects the anchor boxes, bounding box regression offsets help to adjust the anchor boxes to fit the region of interest by moving them around the body part.
Keypoint Head
The Keypoint head in DensePose helps with localizing keypoints in the human body (such as joints), these are then used to estimate the pose of the person. It works by generating a heatmap for various body parts (each body part has its heatmap channel), where each key point is represented with the highest value.
Moreover, the key point head is useful for various indirect functions such as improving DensePose estimation by serving as an auxiliary supervisor, as the key points serve as training signals.
RoI Align
The RoI Align layer in DensePose ensures that the features extracted from each region of interest (human body regions) are accurately aligned and represented. The RoI Align layer differs from standard RoI pooling. The problem with the RoI pooling layer is that it extracts fixed-size feature maps from the region of interest proposed.
Moreover, it also quantifies the coordinates of the region to discrete values (it is a process where the continuous coordinates of the extracted regions of interest are rounded to the nearest integer grid points). This is a problem, especially in tasks that require high precision, such as DensePose estimation.
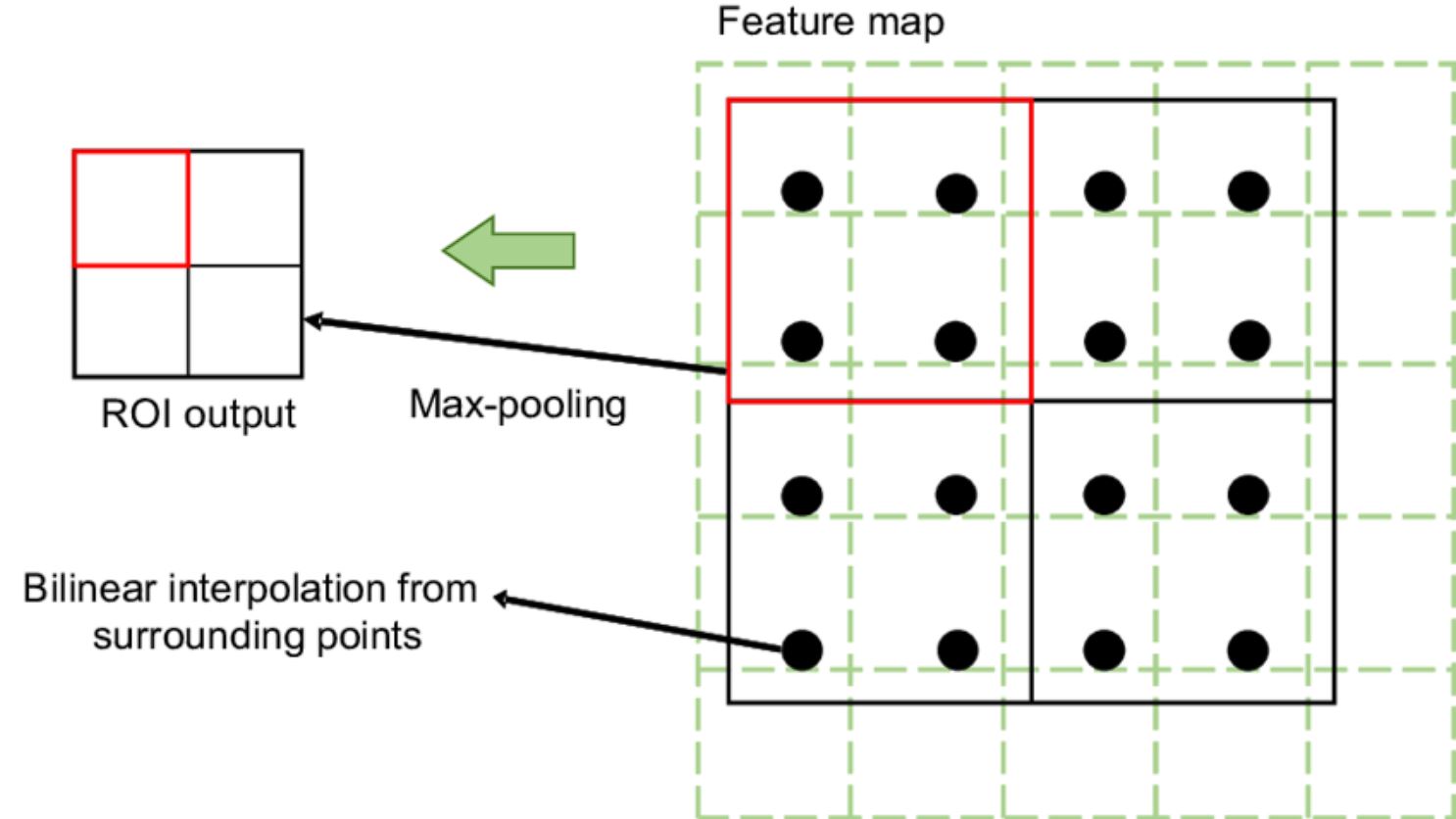
The RoI align layer overcomes the limitations by eliminating the quantization of RoI boundaries by using bilinear interpolation (interpolation is a mathematical technique that estimates unknown values that fall between known values in a sequence). Bilinear interpolation extends linear interpolation to two dimensions.
DensePose-RCNN
A region proposal network draws bounding boxes around parts of an image where human body parts are likely to be found. The output from RPN is a set of region proposals.
Additionally, DensePose uses a Mask-RCNN (an extension of Faster-RCNN). The difference between Faster-RCNN and Mask-RCNN is the use of separate heads for instance segmentation mask prediction, which is a branch that predicts binary mask (using bilinear interpolation).
Therefore, DensePose-RCNN is formed by combining the segmentation mask with dense pose estimation.
Segmentation Mask Prediction
This is a separate branch inside the RPN network for the segmentation of different body parts in the human body.
However, to perform segmentation prediction, the following steps take place:
- The Region Proposal Network generates bounding boxes around the candidate regions that are likely to contain objects (in this case, humans).
- RoI Align is applied to these proposals for precise alignment of the proposed regions.
- Finally, the segmentation task is performed. A dedicated branch in the network processes the aligned features to predict binary masks for each proposed region. This branch consists of several convolutional layers that output a mask for each region of interest, that indicates the presence of body parts.
Finally, the DensePose head takes different segmented body parts and maps them to a continuous surface that outputs the UV coordinates.
Training the DensePose Model
The DensePose model is trained on the COCO-DensePose, an extension of the original COCO dataset. The additional images contain the human body annotated with labels that map image pixels to the 3D surface of the human model.
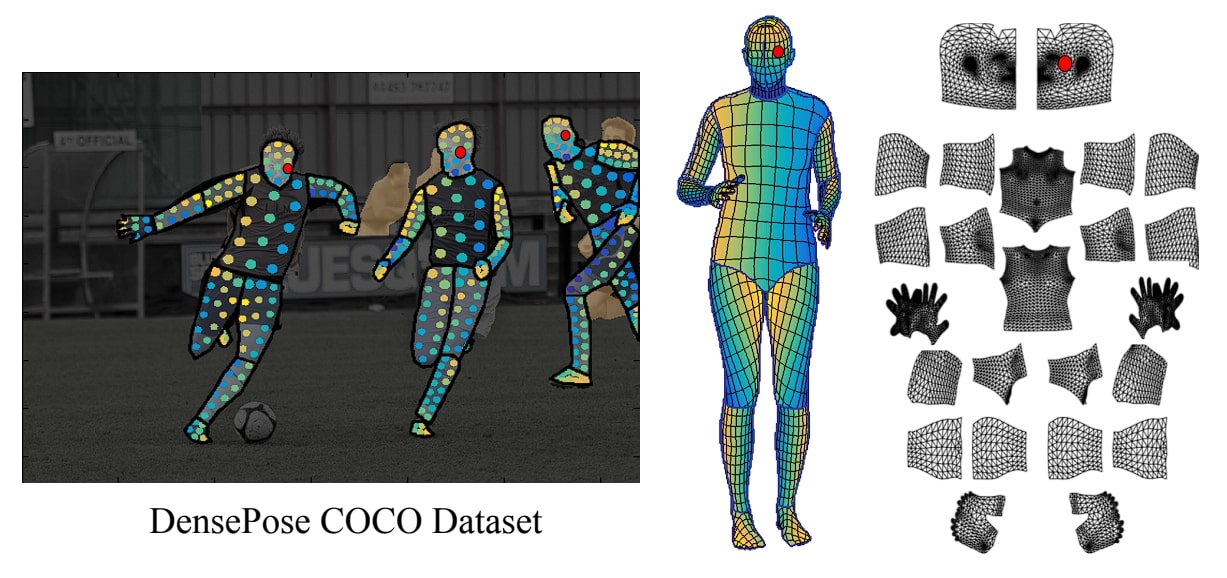
The annotators first segment the body into different parts such as the head, torso, and legs. Then each 2D image is mapped to a 3D human model by creating dense correspondence mapping pixels from 2D images to UV coordinates on the 3D model.
Applications of DensePose
The DensePose model with its dense pose estimation offers integration into diverse fields. We will look at possible scenarios where the model can be implemented in this section.
Augmented Reality (AR):
The field of AR gets a boost due to DensePose. As AR depends upon cameras and sensors, DensePose provides an opportunity to overcome the hardware prerequisites. This allows for a better and more seamless experience for the users. Moreover, using DensePose we can create virtual avatars of the users, and allow them to try on different outfits and apparel in the simulation.

Animation and VFX
The model can be used to generate and simplify the process of character animations, where the human motion is captured and then transferred to digital characters. This can be used in movies, games, and simulation purposes.
Sports Analysis
DensePose model can be used in sports to analyze athlete performance. This can be done by tracking body movements and postures during training and competitions. The data generated can then be used to understand movement and biomechanics for coaching and analytic purposes.

Medical Field
The medical field and especially chiropractors can use DensePose to analyze body posture and movements. This can equip the doctors better for treating patients.
E-Commerce
DensePose can be used by customers to virtually try on clothes and accessories, and visualize how they would look in them before they commit to buying decisions. This can improve customer satisfaction and provide a unique selling point for the businesses.
Moreover, they can also offer personalized fashion recommendations, by using the DensePose model to first capture the user’s body and then create avatars that resemble them.
Limitations of DensePose
In the previous section, we discuss the potential uses of the model. However, there are limitations that DensePose faces, and therefore it requires further research and improvement in these key areas.
Lack of 3D Mesh
Although DensePose provides 3D mesh coordinates, it does not yield 3D representation. There is still a developmental gap between converting an RGB image to a 3D model directly.
Lack of Mobile Integration
Another key limitation of the DensePose model is its dependency on computational resources. This makes it difficult to integrate DensePose into mobile and handled gadgets. However, using cloud architectures to do the computation can fix this problem.
But, this creates a high dependence on the availability of high-speed internet connection. A majority of people lack high-speed connections at home.
Dataset
The key reason that DensePose can perform dense pose estimation is due to the dataset used. Creating the DensePose-COCO dataset required extensive human annotation and time resources, and given these, there are only 50k images with UV coordinates for 24 body parts with a resolution of 256 x 256. This is a limiting factor in terms of training and accuracy of the model. A denser UV correspondence points could make the model perform better.
Conclusion
In this blog, we looked at the architecture of DensePose, a dense pose estimation model developed by researchers at Facebook. It extends the standard Mask-RCNN framework by adding a UV mapping head. The model takes in a picture and uses a backbone network to extract features of the image, then the Region Proposal Network generates possible candidates in the image that likely contain humans.
The RoI Align layer further improves the regions detected, and then this is passed to the segmentation branch which detects different human body parts. For pose estimation, a keypoint head is used to detect joints and key points in the human body. Finally, the DensePose head maps the body parts to UV coordinates for accurate dense pose estimation.
One of the key factors that make the DensePose model impressive is the creation of a dedicated dataset for its training, where the human annotators map parts of the human body to a 3D model.
Read about other Deep Learning models in our interesting blogs below:
- AlphaPose: A Comprehensive Guide to Pose Estimation
- The Complete Guide to OpenPose
- CycleGAN: How AI Creates Stunning Image Transformations
- StyleGAN Explained: Revolutionizing AI Image Generation
Viso Suite Infrastructure
Viso Suite provides fully customized, end-to-end solutions with edge computing capabilities. With cameras, sensors, and other hardware connected to Viso Suite computer vision infrastructure, enterprises can easily manage the entire application pipeline. Learn more about Viso Suite by booking a demo with our team.